Hadoop
Data is kept on low-cost commodity servers that are clustered together. Concurrent processing and fault tolerance are possible with the distributed file system. Hadoop, created by Doug Cutting and Michael J, use the Map Reduce programming paradigm to store and retrieve data from its nodes more quickly. The Apache Software Foundation manages the framework, which is released under the Apache License 2.0. While application servers' processing power has increased dramatically in recent years, databases have lagged behind due to their limited capacity and speed.
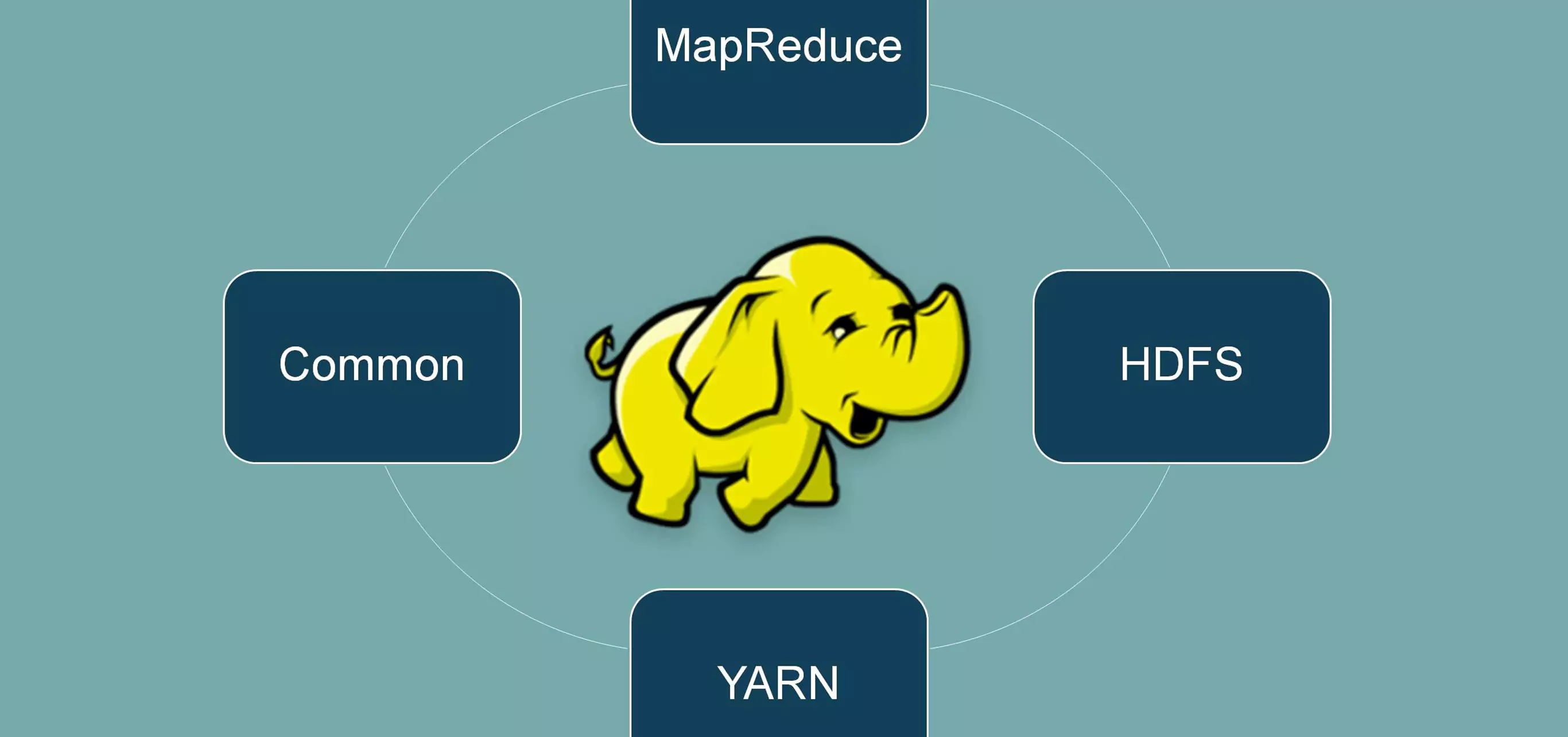
Had Loop was created by Doug Cutting and Michael J and employs the Map Reduce programming architecture to store and retrieve data from its nodes more quickly. From a business standpoint, there are both direct and indirect benefits. To save money for organisations, open-source technology is installed on low-cost servers, which are largely in the cloud (though occasionally on-premises). Additionally, the ability to collect large amounts of data and derive insights from that data leads to better real-world business decisions, such as the ability to focus on the right customer segment, eliminate or fix inefficient processes, optimise floor operations, provide relevant search results, perform predictive analytics, and so on. Hadoop is a distributed data storage and processing architecture made up of multiple interrelated components. The Hadoop ecosystem is made up of these components. Some are required core components, while others are optional enhancements to Hadoop's capabilities. From a business standpoint, there are both direct and indirect benefits. To save money for organisations, open-source technology is employed on low-cost servers, which are typically in the cloud (though occasionally on-premises).
- There is Fault Tolerance Available.
- There is a lot of availability.
- Hadoop Provides Cost-Effective Flexibility.
- Simple to Use.
- At Affordable price.